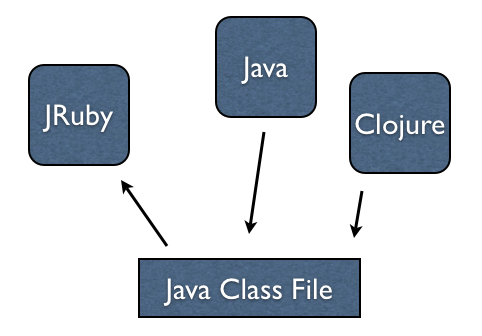
Ruby program on JRuby can talk to Java and Java program with JRuby
libraries can talk to Ruby.
There are many tutorials how to talk to Java on JRuby. It is
certainly useful for most programmers in the way that you can use
plenty of resources in Java platform. It is also important that you
don't have to know Java very much when you use JRuby.
On the other hand there are less tutorials how to talk to Ruby from
Java side. This post will explain both sides that communication
from Ruby to Java and from Java to Ruby.
Ruby talks to Java
Assume you already have Hi.java below.
class Hi {
public Hi() {
}
void f() {
System.out.println("hi");
}
}
Compile the code and generate JAR file.
$ javac Hi.java
$ jar cf hi.jar Hi.class
Next it's turn to write Ruby code. Write the following code into
hi.rb.
require 'hi.jar'
Java::Hi.new.f
Run it.
$ jruby -v hi.rb
hi
Cool! You can run the code on JRuby without setting $PATH.
$ /Users/ujihisa/git/jruby/bin/jruby hi.rb
hi
You wrote Java::Hi.new.f but do you want to abbreviate Java?
Write the following code instead.
require 'hi.jar'
include_class Java::Hi
Hi.new.f
You also can pass some Ruby objects to Java and get Ruby objects
from Java with JRuby.
Hi.java:
class Hi {
public Hi() {
}
int f(int n) {
return n + 1;
}
}
hi.rb:
require 'hi.jar'
include_class Java::Hi
p Hi.new.f(10)
result:
11
Fixnum in Ruby was automatically converted as int in Java
bidirectionally.
Anyway, now you can talk to Java; you can use Java classes from
Ruby.
Handling Ruby objects in Java world
Let me show how to return a Ruby object in Java without using a
ruby code.
The following method just returns the argument.
Hi.java:
class Hi {
public Hi() {
}
Object f(Object x) {
return x;
}
}
hi.rb:
require 'hi.jar'
include_class Java::Hi
obj = Object.new
p Hi.new.f(obj) #=> #<Object:0xf8acdc>
This certainly works, but the Java code lacks the type information;
The Object is the class in Java which means void in C roughly,
but you actually wanted to represent Object in Ruby.
Object in Ruby is IRubyObject in Java with jruby library. I
mean, you should use it instead of just Object.
import org.jruby.runtime.builtin.IRubyObject;
class Calc {
public Calc() {}
IRubyObject f(IRubyObject n) {
return n;
}
}
Note that I wrote import statement in the top of the code.
To compile the code, you have to specify jruby.jar file.
$ javac -classpath /Users/ujihisa/git/jruby/lib/jruby.jar Hi.java
Then after you made new JAR file you can run the same Ruby code in
securer way.
Hi.java
import org.jruby.runtime.builtin.IRubyObject;
import org.jruby.RubyObjectAdapter;
import org.jruby.javasupport.JavaEmbedUtils;
class Hi {
public Hi() {
}
IRubyObject f(IRubyObject x) {
RubyObjectAdapter adapter = JavaEmbedUtils.newObjectAdapter();
return adapter.callMethod(x, "greeting");
}
}
hi.rb
require 'hi.jar'
include_class Java::Hi
obj = Object.new
def obj.greeting
"how are you?"
end
p Hi.new.f(obj) #=> "how are you?"
Java talks to Ruby
I've told about examples which bootstrap was Ruby. Next let's try
to do the same thing from the opposite side. You make a Ruby class
first, and then you use the class from Java.
Hi.java:
import org.jruby.embed.ScriptingContainer;
class Hi {
public static void main(String[] args) {
ScriptingContainer c = new ScriptingContainer();
c.runScriptlet("p 1");
}
}
and run it by the following code:
$ javac -classpath /Users/ujihisa/git/jruby/lib/jruby.jar Hi.java
$ java -classpath /Users/ujihisa/git/jruby/lib/jruby.jar:. Hi
Note that you have to specify the classpath not only in javac
command but also in java command.
You can check the version of JRuby library by writing
c.runScriptlet("p RUBY_DESCRIPTION");.
A complex example
Ruby calls a Java class which method calls Ruby method.
hi.rb
require 'hi.jar'
include_class Java::Hi
Hi.new(2).plus('3').show
Hi.java
import org.jruby.Ruby;
import org.jruby.RubyObjectAdapter;
import org.jruby.runtime.builtin.IRubyObject;
import org.jruby.javasupport.JavaEmbedUtils;
class Hi {
int x;
int y;
public Hi(int n) {
this.x = n;
this.y = 0;
}
Hi plus(IRubyObject s) {
RubyObjectAdapter adapter = JavaEmbedUtils.newObjectAdapter();
this.y = Integer.parseInt(adapter.callMethod(s, "succ").asJavaString());
return this;
}
void show() {
System.out.printf("%s * (%s + 1) = %s\n", this.x, this.y, this.x + this.y);
}
}
result:
2 * (4 + 1) = 6
Postscript
I explained how to execute a Ruby functionality like sending a
message to an object and how to evaluate a Ruby code (parsing and
execution). You may notice that there lacks the information how to
parse a Ruby code without execution. Currently there is no way to
do on JRuby, so I'm working on solving the challenge in a slow
manner.
References